三、应用实例
下面我们来看看Jakarta-ORO库的一些应用实例。
3.1 日志文件处理
任务:分析一个Web服务器日志文件,确定每一个用户花在网站上的时间。在典型的BEA WebLogic日志文件中,日志记录的格式如下:

分析这个日志记录,可以发现,要从这个日志文件提取的内容有两项:IP地址和页面访问时间。你可以用分组符号(圆括号)从日志记录提取出IP地址和时间标记。
首先我们来看看IP地址。IP地址有4个字节构成,每一个字节的值在0到255之间,各个字节通过一个句点分隔。因此,IP地址中的每一个字节有至少一个、最多三个数字。图八显示了为IP地址编写的正则表达式:

图八:匹配IP地址
IP地址中的句点字符必须进行转义处理(前面加上“\”),因为IP地址中的句点具有它本来的含义,而不是采用正则表达式语法中的特殊含义。句点在正则表达式中的特殊含义本文前面已经介绍。
日志记录的时间部分由一对方括号包围。你可以按照如下思路提取出方括号里面的所有内容:首先搜索起始方括号字符(“[”),提取出所有不超过结束方括号字符(“]”)的内容,向前寻找直至找到结束方括号字符。图九显示了这部分的正则表达式。

图九:匹配至少一个字符,直至找到“]”
现在,把上述两个正则表达式加上分组符号(圆括号)后合并成单个表达式,这样就可以从日志记录提取出IP地址和时间。注意,为了匹配“- -”(但不提取它),正则表达式中间加入了“\s-\s-\s”。完整的正则表达式如图十所示。
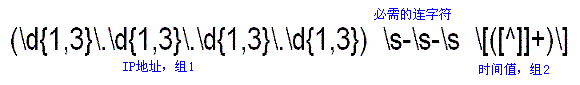
图十:匹配IP地址和时间标记
现在正则表达式已经编写完毕,接下来可以编写使用正则表达式库的Java代码了。
为使用Jakarta-ORO库,首先创建正则表达式字符串和待分析的日志记录字符串:
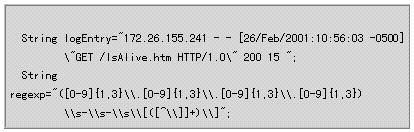
这里使用的正则表达式与图十的正则表达式差不多完全相同,但有一点例外:在Java中,你必须对每一个向前的斜杠(“\”)进行转义处理。图十不是Java的表示形式,所以我们要在每个“\”前面加上一个“\”以免出现编译错误。遗憾的是,转义处理过程很容易出现错误,所以应该小心谨慎。你可以首先输入未经转义处理的正则表达式,然后从左到右依次把每一个“\”替换成“\\”。如果要复检,你可以试着把它输出到屏幕上。
初始化字符串之后,实例化PatternCompiler对象,用PatternCompiler编译正则表达式创建一个Pattern对象:

现在,创建PatternMatcher对象,调用PatternMatcher接口的contain()方法检查匹配情况:

接下来,利用PatternMatcher接口返回的MatchResult对象,输出匹配的组。由于logEntry字符串包含匹配的内容,你可以看到类如下面的输出:
